| Capítulo 6. El programa ensamblador | ||
|---|---|---|
 |

|
|
| Capítulo 6. El programa ensamblador | ||
|---|---|---|
|
|
|
|
Tabla de contenidos
Los programas escritos en lenguaje ensamblador, a pesar de representar instrucciones del lenguaje máquina del procesador, no son directamente ejecutables por éste sino que es necesario traducirlas a su codificación en binario. Este proceso de traducción es fácilmente automatizable, y por tanto se dispone de programas denominados ensambladores (o más genéricamente compiladores que se encargan de esta tarea.
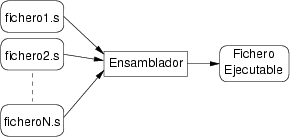
El ensamblador es un programa que recibe como datos de entrada uno o varios ficheros de texto plano con un conjunto de instrucciones y datos escritos en lenguaje ensamblador y produce un fichero binario y ejecutable que contiene la codificación binaria del programa. La figura 6.1 muestra el funcionamiento del programa ensamblador.
En general, a los programas encargados de traducir de un lenguaje de programación a otro se les denomina “compiladores” y todos ellos trabajan de forma similar. Dado un conjunto de ficheros escritos en un lenguaje, producen como resultado otro fichero que contiene la traducción a un segundo lenguaje. En el caso del ensamblador, la traducción es de lenguaje ensamblador a lenguaje máquina.
En adelante se utilizarán los términos “compilador” y “ensamblador” de forma indistinta y siempre en referencia al programa que traduce de lenguaje ensamblador a lenguaje máquina.
Así como el lenguaje máquina de un procesador es único e inmutable (a no ser que se rediseñe el procesador), pueden coexistir múltiples lenguajes ensamblador que representen el mismo lenguaje máquina. La representación de las instrucciones mediante cadenas alfanuméricas es un convenio utilizado para facilitar su escritura, por lo que pueden existir múltiples convenios de este tipo siempre y cuando se disponga del ensamblador los que traduzca al lenguaje máquina del procesador.
En el caso concreto del sistema operativo Linux, se incluye como parte de las herramientas del sistema un compilador capaz de traducir de lenguaje ensamblador a lenguaje máquina. Su nombre es as. En la práctica este programa lo suelen invocar otros compiladores tales como gcc que es un compilador del lenguaje de alto nivel C a lenguaje máquina, pero también permite la traducción de ficheros con código ensamblador invocando internamente el programa as.
La figura 6.2 muestra un programa en lenguaje ensamblador creado mediante un editor de texto plano, un programa que guarda únicamente el texto codificado en formato ASCII o UNICODE sin información alguna sobre estilo. El primer paso, por tanto, para la obtención de un programa ejecutable es la creación de un fichero de texto que contenga el código.
Un programa consta de varias secciones separadas cada una de ellas por
palabras clave que comienzan por el símbolo “.”. La palabra
.data que aparece en la primera línea no tiene traducción
alguna para la ejecución, sino que es la forma de notificar al
ensamblador que a continuación se encuentran definidos conjunto de
datos. A este tipo de palabras que comienzan por punto se les denomina
“directivas”.
El programa tiene definido un único dato que se representa como una
secuencia de caracteres. La línea que contiene .asciz
(también una directiva) seguida del string entre comillas es la que
instruye al ensamblador para crear una zona de memoria con datos, y
almacenar en ella el string que se muestra terminado por un byte con
valor cero. El efecto de la directiva .asciz es que, al
comienzo de la ejecución de programa, este string esté almacenado en
memoria.
Antes de la directiva .asciz se incluye la palabra
dato seguida por dos puntos. Esta es la forma de definir una
etiqueta o nombre que luego se utilizará en el código para acceder a
estos datos.
La línea siguiente contiene la directiva .text que denota el
comienzo de la sección de código. La directiva .global main
comunica al ensamblador que la etiqueta main es globalmente
accesible desde cualquier otro programa.
A continuación se encuentran las instrucciones en ensamblador propiamente
dichas. Al comienzo del código se define la etiqueta main
que identifica el punto de arranque del programa.
Una vez creado y guardado el fichero de texto con el editor, se debe
invocar el compilador. En una ventana en el que se ejecute un intérprete
de comandos y situados en el mismo directorio en el que se encuentra el
fichero ejemplo.s se ejecuta el siguiente comando:
gcc -o ejemplo ejemplo.s
El compilador realiza una tarea similar a la de un compilador de un
lenguaje de alto nivel como Java. Si hay algún error en el programa se
muestra la línea y el motivo. Si el proceso de traducción es correcto, se
crea un fichero ejecutable. En el comando anterior, se ha instruido al
ensamblador, por medio de la opción -o ejemplo para que
el programa resultante se deposite en el fichero con nombre
ejemplo.
El compilador también es capaz de procesar más de un fichero de forma simultanea. Esto es útil cuando el código de un programa es muy extenso y está fraccionado en varios ficheros que deben combinarse para obtener un único ejecutable. En tal caso el comando para compilar debe incluir el nombre de todos los ficheros necesarios.
Si el compilador no detecta ningún error en la traducción, el fichero
ejemplo está listo para ser ejecutado por el
procesador. Para ello simplemente se escribe su nombre en el intérprete
de comandos (en la siguiente línea, el símbolo $
representa el mensaje que imprime siempre el intérprete de comandos):
$ejemplo Mi Primer Programa Ensamblador$
Todo programa ensamblador debe seguir el siguiente patrón:
.data # Comienzo del segmento de datos
<datos del programa>
.text # Comienzo del código
.global main # Obligatorio
main:
<Instrucciones>
ret # Obligatorio
Se pueden incluir comentarios en el código a partir de símbolo “#” hasta el final de línea y son ignorados por el compilador. Basado en este patrón, el programa de la figura 6.2 ha ejecutado las instrucciones:
push %eax
push %ecx
push %edx
push $dato
call printf
add $4, %esp
pop %edx
pop %ecx
pop %eax
ret
Las primeras tres instrucciones depositan los valores de los registros
%eax, %ecx y %edx en la pila. Las
tres instrucciones siguientes se encargan de poner la dirección del
string también en la pila (instrucción push), invocar la
rutina externa printf que imprime el string (instrucción
call) y sumar una constante al registro %esp
para restaurar el valor inicial del puntero a la cima de la pila. Las
tres últimas instrucciones restauran el valor original en los registros
previamente guardados en la pila.
A continuación se estudia en detalle la sintaxis de las diferentes construcciones permitidas en el lenguaje ensamblador.
Como todo lenguaje de programación, se permiten definir tipos de datos
así como su contenido. En el caso del ensamblador, estos tipos no
permiten estructuras complejas ni heterogéneas. Todas las definiciones
deben incluirse en una sección del código que comience por la directiva
.data. Los datos se almacenan en posiciones contiguas de
memoria, es decir, dos definiciones seguidas hacen que los datos se
almacenen uno a continuación de otro.
La principal dificultad para manipular los datos en ensamblador es que cuando el procesador accede a ellos, no se realiza ningún tipo de comprobación. Aunque se definan datos con cierto tamaño y estructura en memoria, el procesador trata estos datos como una simple secuencia de bytes. Esta es una diferencia sustancial con los lenguajes de programación de alto nivel tales como Java. La definición de datos en ensamblador se realiza a través de directivas (descritas a continuación) que únicamente reservan espacio en memoria con los datos pertinentes, pero no se almacena ningún tipo de información sobre su tamaño.
Los lenguajes de alto nivel contienen lo que se conoce como un “sistema de tipos” que consiste en un conjunto de reglas que permiten la definición de tipos de datos así como el mecanismo para comprobar su corrección. En ensamblador, al tratarse de los datos que manipula directamente el procesador, no se dispone de tal sistema, y por tanto se manejan como si fuese simples secuencias de bytes.
La definición de valores numéricos almacenados en bytes se realiza
mediante la directiva .byte seguida de uno o varios
valores separados por comas. Cuando el programa comienza la ejecución,
se han inicializado tantas posiciones en memoria como indica la
directiva con los valores dados. El ejemplo 6.1
muestra ejemplos de utilización de la directiva .byte así
como los valores almacenados en memoria.
Si el valor numérico especificado es menor que cero o mayor que 255 el compilador notifica la anomalía con un error.
La definición de enteros de 32 bits se hace mediante la directiva
.int seguida de un número o una lista de números enteros
separados por comas. Los números se codifican con 4 bytes almacenados
en little endian. El ejemplo 6.2 muestra ejemplos de definiciones de enteros.
La directiva .long es un sinónimo de .int y
también define enteros de 32 bits. Las directivas .word y
.quad son análogas a las anteriores pero definen enteros
de 16 y 64 bits respectivamente.
La definición de strings se puede hacer con dos formatos diferentes
mediante la utilización de tres directivas. La directiva
.ascii permite la definición de uno o más strings entre
comillas y separadas por comas. Cada símbolo de cada strings codifica
con un byte en ASCII utilizando posiciones
consecutivas de memoria. Se utilizan tantos bytes como la suma de los
símbolos de cada string.
La directiva .asciz es similar a la anterior, se escribe
seguida de uno o más strings separados por comas, pero cada uno de
ellos se codifica añadiendo un byte con valor cero a final del
string. Este formato se suele utilizar para detectar el final del
string. La directiva .string es un sinónimo de la
directiva .asciz.
El ejemplo 6.3 muestra la utilización de las
directivas de definición de strings y los valores que se almacenan en
memoria. Los bytes resaltados corresponden son los que añaden las
directivas .asciz y .string al final de cada
string.
La directiva .space seguida de dos números separados por
una coma permite la reserva de espacio en memoria. El primer valor
denota el número de bytes que se reservan y el segundo es el valor que
se utiliza para inicializar dichos bytes y debe estar entre 0 y 255. En
el caso de que este parámetro se omita, la memoria se reserva pero no
se inicializa a ningún valor.
El uso principal de esta directiva es para reservar espacio que, o se debe inicializar al mismo valor, o su valor será calculado y modificado por el propio programa. El ejemplo 6.4 muestra el uso de la directiva así como su efecto en memoria.
En lenguaje ensamblador se permite la definición de un conjunto de datos y las instrucciones para manipularlos que se traducen a su codificación binaria y se produce un fichero ejecutable. Antes de comenzar la ejecución del programa, los datos e instrucciones en binario se cargan en la memoria RAM del sistema. Pero ¿en qué posición de memoria está almacenado el programa?
El valor de esta dirección de memoria, o de la dirección en la que está almacenado cualquier dato o instrucción, no se sabe hasta el momento en el que se ejecuta el programa porque es el sistema operativo el que lo decide, y tal decisión se aplaza hasta el último instante para así poder ubicar cada programa en el lugar más conveniente en memoria. El sistema operativo está ejecutando múltiples programas de forma simultánea, y por tanto, necesita esta flexibilidad para poder hacer un mejor uso de la memoria.
Pero, si no se sabe el valor de la dirección de memoria de ningún dato ni instrucción, ¿cómo se puede, por ejemplo, acceder a un dato en memoria? Para ello se precisa su dirección, pero el valor numérico de esta no se sabe cuando se escribe un programa.
El lenguaje ensamblador soluciona este problema mediante el uso de “etiquetas”. Las etiquetas no son más que nombres que se ponen al comienzo de una línea (ya sea definición de datos o una instrucción) seguido por dos puntos. Dicho nombre representa la posición de memoria en la que está almacenado el dato o instrucción definido justo a continuación.
Estas etiquetas son, por tanto, un punto de referencia en memoria que el ensamblador sabe interpretar de forma correcta y que en el momento de ejecución serán reemplazados por el valor numérico de la dirección de memoria pertinente.
La definición de una etiqueta no sólo permite referirse a los datos
almacenados en esa posición, sino que ofrece un mecanismo por el que
acceder a los datos en posiciones cercanas a ella mediante simples
operaciones aritméticas sobre la dirección que representa. Considérese de
nuevo la representación en memoria de los enteros definidos en el ejemplo 6.2. La figura 6.3 ilustra
como se pueden deducir las direcciones de los demás enteros en base al
símbolo nums:.
Dado que la directiva .int define valores enteros
representados por 32 bits, de la definición de la etiqueta
nums se pueden deducir los valores de las direcciones en
las que se almacenan el resto de números enteros definidos. Para efectuar
estos cálculos es imprescindible saber el tamaño de la información
almacenada a partir de la etiqueta.
Las etiquetas, por tanto, se pueden definir en cualquier lugar del código y son únicamente símbolos que representan una dirección de memoria cuyo valor no se sabe y se utilizan como puntos de referencia para acceder a los datos en memoria de su alrededor. Pero su uso en ensamblador tiene dos versiones igualmente útiles. La primera es acceder al valor contenido en la posición de memoria a la que se refieren. Para ello se incluye en las instrucciones ensamblador el nombre de la etiqueta tal cual se ha definido (sin los dos puntos).
Pero a menudo es necesario manipular la propia dirección de memoria que
representa dicha etiqueta. Aunque dicho valor es desconocido, nada impide
que se escriban instrucciones máquina que operen con él. El ensamblador
permite referirse al valor de la dirección de memoria que representa una
etiqueta precediendo su nombre del símbolo $.
Si una instrucción ensamblador contiene como operando el nombre de una
etiqueta, este operando es de tipo dirección de memoria (ver la sección 5.3.3). En cambio, si el operando es el nombre
de una etiqueta precedido por $, este operando es de tipo
constante.
Esta nomenclatura para diferenciar entre el valor al que apunta una
etiqueta y su valor como dirección en memoria es consistente con la
nomenclatura de operandos. Dada una etiqueta, de los dos valores, al que
apunta en memoria y su dirección, es este último el que permanece
constante a lo largo de la ejecución, y por tanto se representa con el
prefijo $. En cambio, el valor en memoria al que apunta es
variable y por ello se representa únicamente por el nombre de la
etiqueta.
El ejemplo 6.5 muestra una porción de código en la que se define una etiqueta y se manipula mediante instrucciones máquina.
Ejemplo 6.5. Definición y manipulación de etiquetas
.data
dato: .int 3, 4
.string "Mensaje"
.byte 17
...
mov dato, %eax
add $5, %eax
mov %eax, dato
movl $4, dato
...
mov $dato, %ebx
add $8, %ebx
...
La etiqueta dato corresponde con la dirección de memoria en
la que está almacenado el entero de 32 bits con valor 3. En el primer
grupo de instrucciones, la instrucción mov dato, %eax mueve
el número 3 al registro %eax. Nótese que el operando carece
del prefijo $ y por tanto se refiere al valor almacenado en
memoria. A continuación se suma la constante 5 y se transfiere el valor
en %eax de nuevo a la posición de memoria referida por
dato.
La instrucción movl $4, dato requiere especial atención. El
sufijo de tamaño es necesario para desambiguarla porque ni la constante
$4 ni el segundo operando contienen información sobre su
tamaño.La información de una etiqueta es únicamente la dirección a la que
representa sin ningún tipo de información sobre el tamaño de los
datos. Por tanto, a pesar de que dato ha sido definida en
una línea en la que se reserva espacio para enteros, cuando se utiliza en
una instrucción y el otro operando tampoco ofrece información sobre el
tamaño, requiere el sufijo.
En el segundo grupo de instrucciones, la instrucción mov $dato,
%ebx carga en el registro %ebx el valor de la
dirección de memoria que representa la etiqueta. Este valor es
imposible de saber en tiempo de programación, pero se puede manipular
al igual que cualquier otro número. Tras ejecutar la última
instrucción, el registro %ebx contiene la dirección de
memoria en la que está almacenada la primera letra del string. Esto se
deduce de las definiciones de datos y sus tamaños. Los dos números
ocupan 8 bytes, con lo que en la posición $dato + 8 se
encuentra la letra “M” del string Mensaje.
Las etiquetas no sólo se utilizan en las definiciones de datos sino también en instrucciones del código. Los destinos de los saltos reciben como operando una dirección de memoria, que por tanto debe ser una etiqueta.
Se pueden definir tantas etiquetas como sea preciso en un programa sin que por ello se incremente el tamaño del programa. Las etiquetas son símbolos que utiliza el programa ensamblador para utilizar en lugar de los valores numéricos de las direcciones que se sabrán cuando el programa comience su ejecución.
El compilador gcc utilizado para traducir de lenguaje
ensamblador a lenguaje máquina asume que el punto de comienzo de programa
está marcado por la presencia de la etiqueta con nombre
main. Por tanto, al escribir un programa que sea traducido
por gcc se debe definir la etiqueta main
en el lugar del código que contenga su primera instrucción máquina.
El desarrollo de programas en ensamblador tiene una serie de particularidades derivadas de la proximidad al procesador con la que se trabaja. Uno de los cometidos de los lenguajes de programación de alto nivel tales como Java es precisamente el ofrecer al programador un entorno en el que se oculten los aspectos más complejos de la programación en ensamblador.
La pila se utiliza como depósito temporal de datos del programa en
ejecución. Las operaciones push y pop permiten
depositar y obtener datos de la pila, pero no son las únicas que
modifican su contenido. El propio procesador también utiliza la pila para
almacenar datos temporales durante la ejecución. Esto implica que los
programas en ensamblador tienen ciertas restricciones al manipular la
pila.
La más importante de ellas es que la cima de la pila debe ser exactamente
la misma antes del comienzo de la primera instrucción de un programa y
antes de la instrucción RET que termina su ejecución. Cuando
se arranca un programa, el sistema operativo reserva espacio para la pila
y almacena el valor pertinente en el registro %esp. Por
motivos que se explican en detalle en el capítulo 8, el
valor de este registro debe ser el mismo al terminar la ejecución de un
programa.
Nótese que el respetar esta regla no implica que la pila no pueda utilizarse. Al contrario, como la cima debe ser idéntica al comienzo y final del programa, las instrucciones intermedias sí pueden manipular su contenido siempre y cuando al final del programa se restaure el valor de la cima que tenía al comienzo.
En un programa, esta limitación se traduce en que cada dato que se deposite en la pila debe ser descargado antes de que finalice el programa. En el medio del código, la pila puede almacenar los datos que el programador considere oportunos.
Además de inicializar el registro %esp, el sistema operativo
también deposita valores en los registros de propósito general. La
ejecución del programa escrito en ensamblador la inicia el sistema
mediante una llamada a la subrutina con nombre main (de ahí
que éste sea el punto de comienzo del programa) y por tanto, los
registros tienen todos ciertos valores iniciales.
La regla a respetar en los programas ensamblador es que al término de la ejecución de un programa, el valor de los registros de propósito general debe ser exactamente el mismo que tenían cuando se comenzó la ejecución (en la práctica no todos los registros deben ser restaurados, pero por simplicidad se ha adoptado la regla para todos ellos).
De nuevo, el que el valor de los registros tenga que ser idéntico al comienzo y al final de un programa no quiere decir que no se puedan utilizar. Simplemente se deben guardar los valores iniciales de aquellos registros que se utilicen y restaurarlos antes de terminar la ejecución.
El lugar más apropiado para guardar los valores iniciales de estos
registros es precisamente la pila. No es preciso reservar espacio de
antemano, pues la pila ya lo tiene reservado, y mediante varias
instrucciones PUSH se depositan los registros que se
modifiquen en el código antes de ejecutar las instrucciones propias del
cálculo. Luego, justo antes del final de la ejecución se restauran
mediante las instrucciones POP. El ejemplo 6.6 muestra una porción de un programa que
modifica los registros %eax, %ebx,
%ecx y %edx,
Ejemplo 6.6. Instrucciones para salvar y restaurar registros
main: push %eax
push %ebx
push %ecx
push %edx
# Instrucciones del programa que modifican los 4 registros
pop %edx
pop %ecx
pop %ebx
pop %eax
ret
Las instrucciones para guardar la copia de los registros que se modifican
se realiza justo al principio del código. De forma análoga, las
instrucciones para restaurar estos valores se realizan justo antes de la
instrucción RET. Asimismo, el orden en el que se salvan y
restauran los registros es el inverso debido a cómo se almacenan en la
pila. El orden en el que se depositan los datos en la pila es
irrelevante, tan sólo se deben restaurar en orden inverso al que se han
depositado.
Todo programa ensamblador, por tanto, debe comenzar y terminar con
instrucciones de PUSH y POP de los registros
que se modifiquen en su interior.
La utilización de la pila para almacenar los valores de los registros
modificados respeta el convenio de mantener la cima de la pila idéntica
al comienzo y final del programa. Como el número de operaciones
PUSH es idéntico al número de operaciones POP,
mientras que en el código interno del programa todo dato que se deposite
en la pila se extraiga, la cima de la pila es idéntica al comienzo y
final.
A la hora de desarrollar programas en ensamblador, se recomienda primero escribir el código interno de un programa y cuando dicho código se suponga correcto completarlo con las instrucciones que salvan y restauran los registros que se modifican. En general, los datos que se almacenan en la pila se hace de forma temporal y deben eliminarse una vez terminada la tarea para la que se han almacenado.
El desarrollo de programas en ensamblador requiere un conocimiento en detalle de la arquitectura del procesador y una meticulosidad extrema a la hora de decidir qué instrucciones y datos utilizar. Al trabajar con el lenguaje máquina del procesador, la comprobación de errores de ejecución es prácticamente inexistente. Si se ejecuta una instrucción con operandos incorrectos, el procesador los interpretará tal y como estipula su lenguaje máquina, con lo que es posible que la ejecución del programa produzca resultados inesperados.
Desafortunadamente no existe un conjunto de reglas que garanticen un desarrollo simple de los programas. Esta destreza se adquiere mediante la práctica y, más importante, mediante el análisis detenido de los errores, pues ponen de manifiesto aspectos de la programación que se han ignorado.
Las recomendaciones que se hacen para el desarrollo de programas en lenguaje de alto nivel adquieren todavía más relevancia en el contexto del lenguaje ensamblador. Sin ser de ninguna manera una lista exhaustiva, se incluyen a continuación las más relevantes.
El valor de los registros y el puntero de pila antes de ejecutar la última instrucción del programa deben ser idénticos a los valores que tenían al comienzo.
Se deben evitar las operaciones innecesarias. Por ejemplo, salvar y restaurar todos los registros independientemente de si son utilizados o no.
Debido al gran número de instrucciones disponibles y a su simplicidad siempre existen múltiples forma de realizar una operación. Generalmente elige aquella que proporciona una mayor eficiencia en términos de tiempo de ejecución, utilización de memoria o registros, etc.
Mantener un estilo de escritura de código que facilite su legibilidad. Escribir las etiquetas a principio de línea, las instrucciones todas a la misma altura (generalmente mediante ocho espacios), separar los operandos por una coma seguida de un espacio, etc.
La documentación en el código es imprescindible en cualquier lenguaje de programación, pero en el caso del ensamblador, es crucial. Hacer uso extensivo de los comentarios en el código facilita la comprensión del mismo además de simplificar la detección de errores. Los comentarios deben ser lo más detallados posible evitando comentar instrucciones triviales. Es preferible incluir comentarios de alto nivel sobre la estructura global del programa y los datos manipulados.
La mayor parte de errores se detectan cuando el programa se ejecuta. No existe una técnica concreta para detectar y corregir un error, pero se debe analizar el código escrito de manera minuciosa. En ensamblador un simple error en el nombre de un registro puede producir que un programa sea incorrecto.
El ejemplo 6.7 muestra un programa de ejemplo
escrito en ensamblador que dados cuatro enteros almacenados en memoria,
suma sus valores y deposita el resultado en el lugar que denota la
etiqueta result.
Ejemplo 6.7. Programa que suma cuatro enteros
.data # Comienza la sección de datos num1: .int 10 num2: .int 23 num3: .int 34 num4: .int 43 result: .space 4 # Deposita aquí el resultado .text # Comienza la sección de código .global main # main es un símbolo global main: push %eax # Salva registros mov num1, %eax # Carga primer número y acumula add num2, %eax add num3, %eax add num4, %eax mov %eax, result # Almacena resultado pop %eax # Restaura registros ret
La sección de definición de datos contiene los cuatro enteros con sus
respectivas etiquetas y los cuatro bytes de espacio vacío en el que se
almacenará su suma. La directiva .space tiene un único
parámetro, con lo que se reserva espacio en memoria pero no se
inicializa.
El programa utiliza el registro %eax para acumular los
valores de los números, por lo que necesita ser salvado en la pila al
comienzo y restaurado al final.
Tras salvar %eax en la pila la siguiente instrucción
simplemente mueve el primer número al registro %eax. No es
posible sumar dos números que están almacenados en memoria, por lo que el
programa carga el primer valor en un registro y luego suma los restantes
números a este registro.
Finalmente, el programa almacena el resultado de la suma en la posición
de memoria con etiqueta result, restaura los registros
utilizados (en este caso sólo %eax) y termina la ejecución
con la instrucción RET.
Escribir el equivalente de las siguientes definiciones de datos en
ensamblador pero utilizando únicamente la directiva
.byte.
.int 12, 0x34, 'A
.space 4, 0b10101010
.ascii "MSG."
.asciz "MSG. "
Dada la siguiente definición de datos:
dato: .int 0x10203040, 0b10
.string "Mensaje en ASCII"
.ascii "Segundo mensaje"
Si la etiqueta dato ser refiere a la posición de memoria
0x00001000, calcular la dirección de memoria de los
siguientes datos:
El byte con valor 0x30 del primer entero definido.
El byte de más peso del segundo número entero definido.
La letra “A” del primer string definido.
El espacio en blanco entre las dos palabras de la última definición.
|
|
|
|
| Capítulo 5. Juego de instrucciones |  |
Capítulo 7. Modos de Direccionamiento |