| Capítulo 8. Construcciones de alto nivel | ||
|---|---|---|
 |

|
|
| Capítulo 8. Construcciones de alto nivel | ||
|---|---|---|
|
|
|
|
Tabla de contenidos
Las aplicaciones que se ejecutan en un ordenador están generalmente programadas en alguno de los denominados lenguajes de alto nivel que los compiladores traducen a ejecutables que contienen secuencias de instrucciones máquina del procesador.
Para facilitar el desarrollo de estas aplicaciones sean eficientes se necesitan mecanismos adicionales tanto a nivel de procesador como de sistema operativo. Por ejemplo, la posibilidad de fragmentar el código en múltiples ficheros, gestión del acceso de símbolos en otros ficheros, etc.
En este capítulo se estudian los mecanismos que facilitan la traducción de programas en lenguajes de alto nivel a programas en ensamblador. Además de la fragmentación de código en múltiples ficheros, se estudia en detalle el procedimiento para la invocación, paso de parámetros y ejecución de subrutinas, y la traducción de estructuras de control presentes en lenguajes de programación a lenguaje ensamblador.
La funcionalidad que ofrece un procesador está basada en sus instrucciones máquina, órdenes muy simples para manipular datos. Pero para programar operaciones más complejas se precisa un lenguaje que sea más intuitivo y que abstraiga o esconda los detalles de la arquitectura del procesador. A este tipo de lenguajes se les denomina “lenguajes de alto nivel” por contraposición al lenguaje ensamblador cuya estructura y construcciones están directamente relacionadas con la arquitectura del procesador que lo ejecuta. La traducción de las operaciones en un lenguaje de alto nivel a secuencias de instrucciones máquina se lleva a cabo por el compilador.
Las principales limitaciones que se derivan del uso del lenguaje ensamblador son:
Las aplicaciones que contengan manejo de datos u operaciones complejas requieren secuencias de instrucciones extremadamente largas, y por tanto, es muy fácil que se introduzcan errores.
El lenguaje ensamblador carece de tipos de datos. A pesar de que existen directivas para definir datos, su efecto no es más que almacenar una secuencia de bytes en memoria. El procesador accede a estos datos como una secuencia de bytes sin información de tamaño ni de su tipo.
Las subrutinas ofrecen un mecanismo básico para ejecutar porciones de código de forma repetida y con diferentes datos, pero no se realiza ningún tipo de comprobación de su correcta invocación.
Los lenguajes de alto nivel solventan estas limitaciones ofreciendo un conjunto de mecanismos para definir y manipular datos. Cada lenguaje tiene su propia sintaxis, o forma de escribir las órdenes, y su semántica, o cómo esas órdenes son traducidas a secuencias de instrucciones máquina.
Al conjunto de reglas para definir y manipular los tipos de datos en un lenguaje de alto nivel se le denomina el “sistema de tipos de datos”. Aquellos lenguajes que estructuran sus datos en base a objetos que se crean a partir de una definición genérica denominada “clase” se les conoce como “lenguajes orientados a objeto”. Java, Smaltalk y C++ son algunos de los múltiples lenguajes con esta característica.
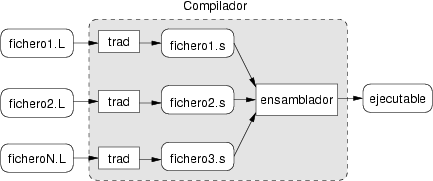
El proceso de compilación de los programas escritos en lenguajes de alto nivel es similar al de traducción de lenguaje ensamblador a lenguaje máquina. Dado un conjunto de ficheros escritos en el lenguaje de entrada, se produce un ejecutable que contiene la traducción de todos ellos a instrucciones máquina y definiciones de datos. La figura 8.1 muestra el procedimiento por el que dado un conjunto de ficheros en lenguaje de alto nivel, el compilador obtiene un fichero ejecutable.
El lenguaje de programación Java merece una mención especial, pues no sigue el patrón de traducción que se muestra en la figura 8.1. Los programas se escriben en múltiples ficheros que contienen la definición de clases con sus campos y métodos. El proceso de compilación no produce directamente un ejecutable sino un fichero con formato “class” o “bytecode”. Este formato no corresponde con instrucciones máquina del procesador sino con instrucciones de lo que se conoce como “máquina virtual de java” o JVM (Java Virtual Machine).
La traducción a código de la JVM se realiza para garantizar la “portabilidad” de un programa, es decir, que el fichero generado se pueda ejecutar sin modificaciones en cualquier procesador. La máquina virtual lee el código escrito en formato class y lo traduce a instrucciones máquina del procesador sobre el que se ejecuta. Esta traducción se hace en el momento en el que se ejecuta un programa. Por este motivo se dice que Java es un lenguaje parcialmente compilado y parcialmente interpretado. La compilación traduce el código inicial a formato bytecode que a su vez es interpretado en tiempo de ejecución por la máquina virtual.
Mediante la presencia de esta máquina virtual, se garantiza la compatibilidad de los programas Java en cualquier procesador. Para ello es preciso crear una máquina virtual diferente para cada uno de los procesadores existentes en el mercado. Una vez implementada esta máquina virtual, todos los programas escritos en Java son ejecutables en esa plataforma.
Existen otro tipo de lenguajes de alto nivel que no precisan de un paso previo de compilación para obtener un ejecutable, sino que se ejecutan directamente a través de un programa auxiliar denominado “intérprete” cuyo cometido es similar al compilador sólo que su tarea la hace justo en el instante que el programa debe ser ejecutado, y no como paso previo. A estos lenguajes de alto nivel se les denomina “interpretados” pues el proceso que se lleva a cabo en el momento de la ejecución es una interpretación del código fuente y su traducción instantánea a código máquina. Perl, Python y TCL son algunos ejemplos de lenguajes de programación interpretados.
La generación de un programa a partir de un conjunto de ficheros con código fuente procesándolos se realiza en dos pasos. En el primero se traduce cada fichero por separado a código máquina. En el segundo paso denominado de “enlazado” (ver sección 1.5.2) se combinan las porciones de código generadas en el paso anterior y se crea el fichero ejecutable. Para ello se precisan dos mecanismos:
Política de acceso a los símbolos definidos en cada uno de los ficheros
Ejecución parcial de un fragmento de código en un fichero diferente al que se está ejecutando y su retorno al mismo punto una vez terminado.
Cada fichero ensamblador contiene un conjunto de etiquetas que representan diferentes posiciones de memoria. Para que un programa pueda ser fragmentado debe ser posible referirse a un símbolo definido en otro fichero. Por ejemplo, una instrucción de salto debe poder especificar como destino un punto en el código de otro fichero.
Pero si una aplicación consta de múltiples ficheros cada uno de ellos con un número muy elevado de etiquetas definidas, tareas como la ampliación de un programa se vuelven muy difíciles. Si los símbolos definidos en los ficheros son todos ellos globales, no se puede utilizar un nombre para una variable o una posición en el código que esté presente en otro fichero.
Para solucionar este problema se adopta la política de gestión opuesta
para el ámbito de los símbolos. Todo símbolo definido en un fichero tiene
como ámbito de validez únicamente el propio fichero a no ser que se
especifique lo contrario con la directiva de ensamblador
.global. De esta forma, cuando se escribe código ensamblador
en un fichero, se puede utilizar cualquier nombre para una etiqueta que
no haya sido declarado como global por otro fichero.
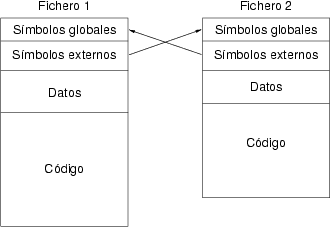
En el primer paso de la traducción, todo símbolo que no esta definido en el fichero que se procesa se considera externo, y por tanto su posición es desconocida. Es en el paso de entrelazado en el que los símbolos son todos conocidos y se pueden traducir a sus correspondientes valores. El compilador incluye en cada fichero obtenido en el primer paso dos conjuntos de símbolos: el primero corresponde con las etiquetas definidas en la zona de datos o de código que han sido declaradas globales, mientras que el segundo contiene aquellos que se utilizan pero cuya definición no se ha encontrado en el fichero. La figura 8.2 muestra un ejemplo de programa escrito en dos ficheros en los que se producen referencias a símbolos externos.
En la fase de entrelazado, para cada fichero, el compilador busca los símbolos externos en la lista de símbolos globales del resto de ficheros. En el caso de que un símbolo externo no esté definido en ninguno de ellos se muestra un mensaje de error. Si dos ficheros definen el mismo símbolo como global también se muestra un mensaje de error. En ambos casos no se produce fichero ejecutable.
Además de los símbolos contenidos en cada uno de los ficheros, en la fase de entrelazado el compilador dispone de código auxiliar en ficheros denominados “bibliotecas” en los que se incluyen rutinas para realizar tareas comunes de cualquier programa como lectura/escritura de datos a través de diferentes dispositivos (teclado, pantalla, ficheros, etc).
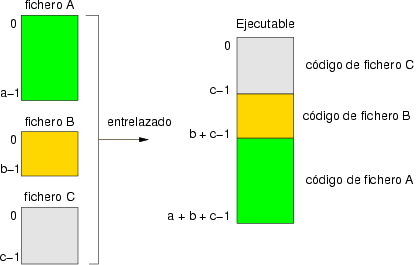
Otro aspecto que debe solventar el compilador para generar un ejecutable a partir de múltiples ficheros fuente es el de la “reubicación de código”. Al traducir el código ensamblador contenido en cada fichero, el código binario resultante se almacena a partir de la posición cero de memoria, pues no se sabe la posición exacta que ocupará a la hora de ejecutar. Pero cuando el código está en múltiples ficheros, en la fase de entrelazado sólo el código de uno de ellos puede estar en la posición inicial, el resto debe ser reubicado. La figura 8.3 muestra un ejemplo en el que el ejecutable se obtiene a partir de tres ficheros. El código de dos de ellos debe ser reubicado.
La reubicación de código consiste en que toda instrucción que contenga en su codificación el valor de una dirección de memoria (por ejemplo, las que utilizan el modo de direccionamiento absoluto) deben ser modificadas para referirse a la posición de memoria tras la reubicación. El compilador recorre de nuevo las instrucciones máquina generadas y suma a toda dirección de memoria un factor de reubicación que corresponde con la dirección utilizada al comienzo del fichero.
Considérese la instrucción call metodo1 que invoca a la
subrutina método definida en otro fichero. En la primera
fase de compilación esta instrucción se traduce por el código
0xE8FCFFFFFF. Los cuatro últimos bytes denotan la dirección
de memoria representada por la etiqueta método. En el
ejecutable obtenido, el código de esta instrucción pasa a ser
0xE8FA000000 que conserva el primer byte que corresponde con
el código de operación pero cambia los cuatro últimos bytes que codifican
la dirección de memoria.
Las construcciones que ofrecen los lenguajes de alto nivel como Java para
escribir programas distan mucho de la funcionalidad ofrecida por el
lenguaje máquina del procesador. Por ejemplo, en Java se permite ejecutar
una porción de código de forma iterativa mediante las construcciones
for o while hasta que una condición se deje de
cumplir. El compilador es el encargado de producir el código ensamblador
tal que su ejecución sea equivalente a la especificada en el lenguaje
Java.
A continuación se muestra cómo la funcionalidad ofrecida por el procesador es suficiente para traducir estas construcciones a secuencias de instrucciones ensamblador con idéntico significado.
La figura 8.4 muestra las tres partes de las
que consta un bloque if/then/else. La
palabra reservada if va seguida de una expresión booleana
entre paréntesis. A continuación entre llaves una primera porción de
código que puede ir seguida opcionalmente de una segunda porción
también entre llaves y con el prefijo else.
Lo más importante para traducir un bloque a ensamblador es saber su significado o semántica. La semántica del bloque if/then/else es que se evalua la expresión booleana y si el resultado es verdadero se ejecuta el bloque A de código y se ignora el bloque B, y si es falsa, se ignora el bloque A y se ejecuta el bloque B.
El elemento clave para traducir esta construcción a ensamblador es la
instrucción de salto condicional. Este tipo de instrucciones permiten
saltar a un destino si una condición es cierta o seguir la secuencia de
ejecución en caso de que sea falsa. Lo único que se necesita es
traducir la expresión booleana de alto nivel a una condición que pueda
ser comprobada por una de las instrucciones de salto condicional
ofrecida por el procesador. Supóngase que la expresión es falsa si el
resultado de la evaluación es cero y cierta en caso contrario. Además,
tras ejecutar las instrucciones de evaluación, el resultado se almacena
en %eax. En la figura 8.5
se muestra la estructura genérica en lenguaje ensamblador resultante de
traducir un if/then/else en este
supuesto.
Figura 8.5. Traducción de un if/then/else a ensamblador
... # Evaluar la expresión booleana
... # Resultado en %eax
cmp $0, %eax
je bloqueb
... # Traducción del bloque A
... # Fin del bloque A
jmp finifthenelse
bloqueb: # Traducción del bloque B
...
... # Fin del bloque B
finifthenelse:
... # Resto del programa
Tras la evaluación de la condición, el resultado previamente almacenado
en %eax se compara, y si es igual a cero se ejecuta el
salto que evita la ejecución del bloque A. En el caso de un
if/then/else sin el bloque B, el salto
sería a la etiqueta finifthenelse.
En un bloque genérico de este tipo no es preciso asumir que el
resultado de la condición está almacenado en %eax. El
ejemplo 8.1 muestra la traducción de un
if/then/else con una condición booleana
con múltiples operaciones. Se asume que las variables x,
i y j son de tipo entero y están almacenadas
en memoria con etiquetas con el mismo nombre.
Ejemplo 8.1. Traducción de un if/then/else a ensamblador
| Código de alto nivel | Código ensamblador |
|---|---|
if ((x <= 3) && (i == (j + 1))) {
Bloque A
} else {
Bloque B
}
|
cmpl $3, x # Comparar si x <= 3
jg bloqueB # Si falso ir a bloque B
mov j, %eax # Obtener j + 1
inc %eax
cmp %eax, i # Comparar i == (j + 1)
jne bloqueB # Si falso ir a bloque B
... # Traducción del bloque A
...
jmp finifthenelse # Evitar bloque B
bloqueB:
... # Traducción del bloque B
...
finifthenelse: # Final de traducción
|
La primer expresión de la conjunción se traduce en una única
instrucción cmp. Si esta comparación no es cierta, al
tratarse de una conjunción, se debe ejecutar el bloque B sin necesidad
de seguir evaluando. Esto se consigue con el salto jg que
contiene la condición contraria a la del código (x <=
3).
Si la primera parte de la conjunción evalúa a cierto, se pasa a evaluar
la segunda. Primero se obtiene el valor de j, se copia en
un registro y se incrementa, pues el código de alto nivel no modifica
el valor almacenado en memoria. A continuación se compara con la
variable i y de nuevo, mediante un salto condicional, se
ejecuta el bloque pertinente.
A menudo en programación es preciso realizar una operación y ejecutar
diferentes bloques de código dependiendo del valor obtenido. La
construcción switch mostrada en la figura 8.6 ofrece exactamente esta funcionalidad
Figura 8.6. Estructura de un switch
switch (expresión) { case valor A: Bloque A break; // Opcional case valor B: Bloque B break; // Opcional ... default: Bloque por defecto // Opcional }
La semántica de esta construcción establece que primero se evalúa la
condición y a continuación se compara el resultado con los valores de
cada bloque precedido por la palabra clave case. Esta
comparación se realiza en el mismo orden en el que se definen en el
código y si alguna de estas comparaciones es cierta, se pasa a ejecutar
el código restante en el bloque (incluyendo el resto de casos). Si
ninguna de las comparaciones es cierta se ejecuta (si está presente) el
caso con etiqueta default. La palabra clave
break se puede utilizar para transferir el control a la
instrucción que sigue al bloque switch.
La estructura del código ensamblador para implementar esta construcción
debe comenzar por el cálculo del valor de la expresión. A continuación
se compara con los valores de los casos siguiendo el orden en el que
aparecen en el código. Si una comparación tiene éxito, se ejecuta el
bloque de código que le sigue. Si se encuentra la orden
break se debe saltar al final del bloque. En el caso de
que ninguna comparación tenga éxito, se debe pasar a ejecutar el bloque
default. Supóngase que la evaluación de la expresión es un
valor que se almacena en el registro %eax. En la figura 8.7 se muestra la estructura genérica en
lenguaje ensamblador resultante de traducir un
switch en este supuesto.
Figura 8.7. Traducción de un switch a ensamblador
... # Evaluar la expresión
... # Resultado en %eax
cmp $valorA, %eax # Caso A
je bloquea
cmp $valorB, %eax # Caso B
je bloqueb
...
jmp default
bloquea:
... # Traducción del bloque A
... #
jmp finswitch # Si bloque A tiene break
bloqueb:
...
...
jmp finswitch # Si bloque B tiene break
...
...
default:
... # Caso por defecto
...
finswitch:
... # Resto del programa
En este esquema se asume que tras obtener el valor de la expresión,
éste se mantiene en el registro %eax. La presencia de la
línea break corresponde directamente con la instrucción
jmp finswitch. El ejemplo 8.2
muestra la traducción de un switch. Se
asume que las variables son todas de tipo entero y están almacenadas en
memoria con etiquetas con el mismo nombre.
Ejemplo 8.2. Traducción de un switch a ensamblador
| Código de alto nivel | Código ensamblador |
|---|---|
switch (x + i + 3 + j) {
case 12:
Bloque A
break;
case 14:
case 16:
Bloque B
case 18:
Bloque C
break;
default:
Bloque D
}
|
mov x, %eax # Evaluar la expresión
add i, %eax
add $3, %eax
add j, %eax
cmp $12, %eax # Caso 12
je bloquea
cmp $14, %eax # Caso 14
je bloqueb
cmp $16, %eax # Caso 16
je bloqueb
cmp $18, %eax # Caso 18
je bloquec
jmp default
bloquea:
... # Traducción del bloque A
... #
jmp finswitch # Bloque A tiene break
bloqueb:
... # Traducción del bloque B
...
bloquec:
... # Traducción del bloque C
...
jmp finswitch # Bloque C tiene break
default:
... # Bloque D
...
finswitch:
... # Resto del programa
|
La condición del ejemplo es una suma de cuatro operandos, con lo que
las instrucciones ensamblador correspondientes obtienen los operandos y
acumulan su suma en %eax. A continuación se comparan los
sucesivos casos. Si alguna de ellas tiene éxito se pasa a ejecutar el
correspondiente bloque de código. Si todas ellas fallan, se ejecuta el
salto incondicional al bloque default. En cada uno de los
bloques, si está presente la palabra reservada break, ésta
se traduce en un salto incondicional al final del bloque.
Una de las construcciones más comunes en lenguajes de alto nivel para
ejecutar código de forma iterativa es el bucle
while. La figura 8.8
muestra su estructura. La palabra reservada while da paso
a una expresión booleana entre paréntesis que se evalúa y en caso de
ser cierta pasa a ejecutar el bloque del código interno tras cuyo final
se vuelve de nuevo a evaluar la condición.
En este bloque es importante tener en cuenta que la expresión booleana
se evalúa al menos una vez y se continúa evaluando hasta que sea
falsa. Supóngase que la evaluación de la expresión es cero en caso de
ser falsa y diferente de cero si es cierta y el valor resultante se
almacena en %eax. En la figura 8.9 se muestra la estructura genérica en
lenguaje ensamblador resultante de traducir un bucle
while en este supuesto.
Figura 8.9. Traducción de un bucle while a ensamblador
eval: ... # Evaluar la expresión booleana
... # Resultado en %eax
cmp $0, %eax
je finwhile
... # Traducción del código interno
...
jmp eval
finwhile:
... # Resto del programa
Tras evaluar la condición se ejecuta una instrucción que salta al final
del bloque si es falsa. En caso de ser cierta se ejecuta el bloque de
código y tras él un salto incondicional a la primera instrucción con la
que comenzó la evaluación de la condición. El destino de este salto no
puede ser la instrucción de comparación porque es muy posible que las
variables que intervienen en la condición hayan sido modificadas por lo
que la evaluación se debe hacer a partir de estos valores. El ejemplo 8.3 muestra la traducción de un bucle
while con una de estas condiciones. Se
asume que las variables x, i y j
son de tipo entero y están almacenadas en memoria con etiquetas con el
mismo nombre.
Ejemplo 8.3. Traducción de un bucle while a ensamblador
| Código de alto nivel | Código ensamblador |
|---|---|
while ((x == i) || (y < x)) {
Código interno
}
|
eval: # Comienza evaluación
mov x, %eax
cmp i, %eax # Comparar si x == i
je codigointerno # Si cierto ejecutar código
cmp y, %eax
jle finwhile # Si falso ir al final
codigointerno:
... # Código interno
...
jmp eval # Evaluar de nuevo
finwhile: # Final de traducción
|
En este caso la condición del bucle es una disyunción con lo que si una
de las condiciones es cierta, se puede ejecutar el código interno del
bucle sin evaluar la segunda. Por este motivo se utiliza el salto
condicional je tras la primera comparación. En caso de
éxito se pasa a ejecutar directamente el bloque de código interno al
bucle. Si la primera condición es falsa se evalúa la segunda. El
correspondiente salto condicional en este caso tiene una condición
inversa a la incluida en el código, pues si ésta es falsa, se debe
transferir el control al final del bucle.
El bucle for, aunque con semántica similar al anterior, tiene una estructura más compleja tal y como se muestra en la figura 8.10.
Figura 8.10. Estructura de un bucle for
for (Bloque A; expresión booleana; Bloque B) { Código interno }
El bloque A se ejecuta una única vez antes del bucle, a continuación se
evalúa la expresión booleana. En caso de ser cierta se pasa a ejecutar
el código interno del bucle, y si no, se termina la ejecución del
bucle. El bloque B se ejecuta a continuación del código interno y justo
antes de saltar de nuevo a la evaluación de la expresión
booleana. Supóngase que la evaluación de la expresión booleana es cero
en caso de ser falsa y diferente de cero si es cierta y el valor
resultante se almacena en %eax. En la figura 8.11 se muestra la estructura genérica en
lenguaje ensamblador resultante de traducir un bucle
for en este supuesto.
Figura 8.11. Traducción de un bucle for a ensamblador
... # Traducción del bloque A
...
eval: ... # Evaluar la expresión booleana
... # Resultado en %eax
cmp $0, %eax
je finfor
... # Traducción del código interno
...
... # Traducción del bloque B
...
jmp eval
finfor:
... # Resto del programa
Las primeras instrucciones corresponden a la traducción del bloque A
seguidas de las que evalúan la condición. Se necesita la etiqueta
eval como destino del salto incondicional al final del
bloque B. A continuación se comprueba el resultado de la comparación, y
si es falso se salta al final del bucle. En caso contrario se ejecuta
el código interno que finaliza con las instrucciones del bloque B y un
salto incondicional para que se evalúe de nuevo la condición. El ejemplo 8.4 muestra la traducción de un bucle
for con una de estas condiciones. Se
asume que las variables i y j son de tipo
entero y están almacenadas en memoria con etiquetas con el mismo
nombre.
Ejemplo 8.4. Traducción de un bucle for a ensamblador
| Código de alto nivel | Código ensamblador |
|---|---|
for (i = 0; i <= --j; i++) {
Código interno
}
|
movl $0, i # Bloque A
eval: # Expresión booleana
mov i, %eax
decl j
cmp j, %eax # Comparar si x <= --j
jg finfor # Si falso ir al final
codigointerno:
... # Código interno
...
incl i # Bloque B
jmp eval # Evaluar de nuevo
finfor: # Final de traducción
|
La traducción del bloque A es una única instrucción que almacena un
cero en memoria. La expresión booleana incluye el decremento de la
variable j antes de ser utilizada por la comparación. La
traducción del bloque B también requiere una única instrucción para
incrementar el valor de la variable i.
En la sección anterior se ha mostrado cómo se obtiene una traducción automática de un programa arbitrariamente complejo. El compilador primero traduce un bloque a su estructura genérica, luego traduce los bloques internos, y una vez terminado, pasa al bloque siguiente. La estructura global de un programa es una combinación de bloques para los cuales existe una traducción sistemática. Esta y la codificación de los datos son las dos principales tareas de un compilador para obtener un ejecutable.
El mecanismo que merece un estudio aparte es el de llamada a subrutinas. El desarrollo de programas modulares se basa en la posibilidad de ejecutar un bloque de código múltiples veces con diferentes valores de un conjunto de variables denominadas “parámetros” que produce un resultado. Este mecanismo, con diferentes matices, es lo que se denomina como procedimientos, funciones, subprogramas o métodos y están presentes en prácticamente todos los lenguajes de programación de alto nivel.
En el contexto del lenguaje ensamblador se define una subrutina como una porción de código que realiza una operación en base a un conjunto de valores dados como parámetros de forma independiente al resto del programa y que puede ser invocado desde cualquier lugar del código, incluso desde dentro de ella misma.
La ejecución de subrutinas tiene las siguientes ventajas:
Evita código redundante. Durante el diseño de un programa suelen existir ciertos cálculos que deben realizarse en diferentes lugares del código. La alternativa a replicar las instrucciones es encapsularlas en una subrutina e invocar esta cada vez que sea necesario lo cual se traduce en código más compacto.
Facilita la descomposición de tareas. La descomposición de tareas complejas en secuencias de subtareas más simples facilita enormemente el desarrollo de programas. Esta técnica se suele aplicar de forma sucesiva en lo que se denomina “diseño descendente” de programas. Cada subtarea se implementa como una rutina.
Facilita el encapsulado de código. El agrupar una operación y sus datos en una subrutina y comunicarse con el resto de un programa a través de sus parámetros y resultados, hace que si en algún momento se cambia su implementación interna, el resto del programa no requiera cambio alguno.
Además de estas ventajas, el encapsulado de código también facilita la reutilización de su funcionalidad en más de un programa mediante el uso de “bibliotecas”. Una biblioteca de funciones es un conjunto de subrutinas que realizan cálculos muy comunes en la ejecución de programas y que pueden ser utilizados por éstos. Java es un ejemplo de lenguaje que dispone de bibliotecas de clases que en su interior ofrecen multitud de métodos.
La desventaja de las subrutinas es que es necesario establecer un protocolo que defina dónde y cómo se realiza esta transferencia de datos para la que se requieren múltiples instrucciones máquina adicionales.
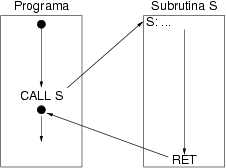
En ensamblador la llamada a una subrutina se realiza mediante la
instrucción CALL cuyo único operando es la dirección de
memoria, generalmente una etiqueta, en la que comienza su código. Tras
ejecutar esta instrucción el procesador continua ejecutando la primera
instrucción de la subrutina hasta que encuentra la instrucción
RET que no tiene operandos y transfiere la ejecución a la
instrucción siguiente al CALL que inició el proceso. La
figura 8.12 ilustra esta secuencia.
La instrucción CALL tiene una funcionalidad similar a un
salto incondicional, su único operando denota la siguiente instrucción
a ejecutar. La instrucción RET no tiene operandos
explícitos pero su efecto, el retorno a la siguiente instrucción tras
la llamada, requiere la utilización de operandos implícitos.
Pero la dirección a la que debe retornar el procesador no puede ser un
valor fijo para la instrucción RET puesto que depende del
lugar desde donde ha sido invocada la subrutina. Considérese, por
ejemplo, una subrutina que se invoca desde dos lugares diferentes de un
programa. La instrucción RET con la que se termina su
ejecución es idéntica en ambos casos pero su dirección de retorno
no. Otra característica de las subrutinas es que su invocación se puede
hacer de forma anidada, es decir, que desde una subrutina se invoca a
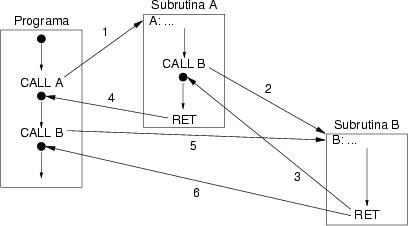
otra y desde ésta a su vez a otra, hasta una profundidad arbitraria. La figura 8.13 muestra un ejemplo de invocación anidada de
subrutinas y se puede comprobar como la subrutina B es invocada desde
diferentes lugares del código.
La instrucción RET de la subrutina B retorna la ejecución
a la subrutina A en su primera ejecución (denotada por la flecha número
3) y al programa principal en su segunda ejecución (denotada por la
flecha número 6). Esto hace suponer, por tanto, que la dirección de
retorno no puede ser decidida cuando se ejecuta esta instrucción sino
en un momento anterior.
El instante en el que se sabe dónde ha de retomarse la ejecución tras
una subrutina es precisamente en el momento de su invocación. Cuando el
procesador está ejecutando la instrucción CALL obtiene la
dirección de retorno como la de la instrucción siguiente en la
secuencia.
Por tanto, el procesador, además de modificar la secuencia, al ejecutar
la instrucción CALL debe guardar la dirección de retorno
en un lugar prefijado del cual será obtenido por la instrucción
RET. Pero, durante la ejecución de un programa es preciso
almacenar múltiples direcciones de retorno de forma simultanea.
El que las subrutinas se puedan invocar de forma anidada hace que la
utilización de los registros de propósito general para almacenar la
dirección de retorno no sea factible. La alternativa es almacenarlas en
memoria, pero la instrucción RET debe tener acceso a su
operando implícito siempre en el mismo lugar. Además, esta zona de
memoria debe poder almacenar un número arbitrario de direcciones de
retorno, pues la invocación de subrutinas se puede anidar hasta niveles
arbitrarios de profundidad.
Por tanto, se necesita un área de memoria que pueda almacenar tantas
direcciones de retorno como subrutinas están siendo invocadas de forma
anidada en un momento de la ejecución de un programa. La propiedad que
tienen estas direcciones es que se almacenan por la instrucción
CALL en un cierto orden, y son utilizadas por la
instrucción RET en el orden inverso.
La estructura especialmente concebida para este propósito es la
pila. En ella se almacena la dirección de retorno mientras se ejecuta
el cuerpo de una subrutina. En caso de invocaciones anidadas, las
direcciones de retorno pertinentes se guardan en la pila y están
disponibles para la instrucción RET en el orden preciso.
La instrucción CALL, por tanto, realiza dos tareas: pasa a
ejecutar la instrucción en la dirección dada como operando y almacena
en la cima de la pila la dirección de la instrucción siguiente (al
igual que lo haría una instrucción PUSH) que será la
instrucción de retorno. Por su parte, la instrucción RET
obtiene el dato de la cima de la pila (igual que lo haría la
instrucción POP) y ejecuta un salto incondicional al lugar
que indica. Ambas instrucciones, por tanto, modifican el contador de
programa.
Del funcionamiento de estas instrucciones se concluye que la cima de la
pila justo antes de la ejecución de la primera instrucción de una
subrutina contiene la dirección de retorno, y por tanto, antes de
ejecutar la instrucción RET debe apuntar exactamente a la
misma posición. Aunque esta condición es esencial para que el retorno
de la subrutina se haga al lugar correcto, los procesadores no realizan
comprobación alguna de que así se produce. Por lo tanto, es
responsabilidad del programador en ensamblador el manipular la pila en
una subrutina de forma que la cima de la pila al comienzo de la
ejecución sea exactamente la misma que justo antes de ejecutar la
última instrucción.
Durante la ejecución de la subrutina se pueden hacer las operaciones
necesarias sobre la pila siempre y cuando se conserve la dirección de
retorno. Esta es la explicación de por qué en la sección 6.4 se estipuló la regla de que la pila
al comienzo y final de un programa debe ser la misma. El programa en
ensamblador que comienza a ejecutar a partir de la etiqueta
main también es una subrutina que invoca el sistema
operativo, y por lo tanto se debe garantizar que la cima es idéntica al
comienzo y al final del programa pues contiene la dirección de retorno.
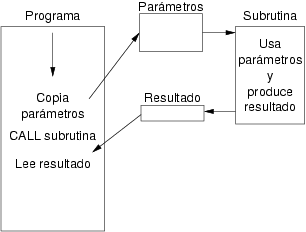
En general una subrutina consiste en una porción de código que realiza una operación con un conjunto de valores proporcionados por el programa que la invoca denominados parámetros, y que devuelve un resultado. Los parámetros son copias de ciertos valores que se ponen a disposición de la subrutina y que tras acabar su ejecución se descartan. El resultado, en cambio, es un valor que la subrutina calcula y copia en un lugar para que el programa invocador lo utilice. La figura 8.14 ilustra la manipulación de parámetros y resultado.
Se necesita establecer las reglas que estipulen cómo y dónde deposita el programa que invoca una subrutina estos valores y cómo y dónde se deposita el resultado. En adelante, a la porción de código que realiza la llamada a la subrutina se le denominará “programa llamador” mientras que al código de la subrutina se le denominará “programa llamado”. Las llamadas a subrutinas se puede hacer de forma “anidada”, es decir, un programa llamado invoca a su vez a otra subrutina con lo que pasa a comportarse como programa llamador.
El paso de parámetros a través de registro consiste en que el programa llamador y el llamado asumen que los parámetros se almacenan en ciertos registros específicos. Antes de la instrucción de llamada el programa llamador deposita los valores pertinentes en estos registros y la subrutina comienza a procesarlos directamente.
En general, dada una rutina que recibe n parámetros y devuelve m
resultados, se necesita definir en qué registro deposita el programa
llamador la copia de cada uno de los n parámetros, y en qué registro
deposita la subrutina la copia del resultado obtenido. El ejemplo 8.5 muestra las instrucciones
necesarias en el caso de una subrutina que recibe como parámetros dos
enteros a través de los registros %eax y %ebx y devuelve
el resultado a través del registro %ecx.
Ejemplo 8.5. Paso de parámetros a través de registros
| Programa llamador | Programa llamado |
|---|---|
mov param1, %eax
mov param2, %ebx
call subrutina
mov %ecx, resultado
|
subrutina:
push %... # Salvar registros utilizados
push %... # excepto %eax, %ebx y %ecx
... # Realizar cálculos
mov ..., %ecx # Poner resultado en %ecx
pop %... # Restaurar registros
pop %...
ret
|
Al utilizar los registros %eax y %ebx para
pasar los parámetros la subrutina no salva su contenido pues dispone
de esos valores como si fuesen suyos. El registro %ecx,
al contener el resultado, tampoco se debe salvar ni restaurar.
El principal inconveniente que tiene este esquema es el número limitado de registros de propósito general. En los lenguajes de alto nivel no hay límite en el número de parámetros que puede tener una función o método en su definición, y por tanto, si este número es muy alto, el procesador puede no tener registros suficientes.
A pesar de esta limitación, en el caso de subrutinas con muy pocos parámetros y que devuelve un único resultado, este mecanismo es muy eficiente pues el procesador no precisa almacenar datos en memoria. Los sistemas operativos suele utilizar esta técnica para invocaciones de subrutinas internas de estas características.
El paso de parámetros a través de memoria consiste en definir una zona de memoria conocida tanto para el programa llamador como para el llamado y en ella se copia el valor de los parámetros y el del resultado para su intercambio. La ventaja de esta técnica radica en que permite tener un número arbitrario de parámetros, pues tan sólo se requiere una zona más grande de memoria.
En general, para una subrutina que recibe n parámetros y devuelve m
resultados se define una zona de memoria cuyo tamaño es la suma de
los tamaños de todos ellos así como el orden en el que estarán
almacenados. El ejemplo 8.6 muestra la
instrucciones necesarias para el caso de una subrutina que precisa
tres parámetros de tamaño 32 bits y devuelve dos resultados de
tamaño 8 bits. Se asume que la zona de memoria está definida a partir
de la etiqueta params.
Ejemplo 8.6. Paso de parámetros a través de memoria
| Programa llamador | Programa llamado |
|---|---|
mov params, %eax
mov v1, %ebx
mov %ebx, (%eax)
mov v2, %ebx
mov %ebx, 4(%eax)
mov v3, %ebx
mov %ebx, 8(%eax)
call subrutina
mov 12(%eax), %ah
mov 13(%eax), %ah
|
subrutina:
push %... # Salvar registros utilizados
push %...
mov params, %ebx # Acceso a los parámetros
mov (%ebx), ...
mov 4(%ebx), ...
mov 8(%ebx), ...
... # Realizar cálculos
mov %dh, 12(%ebx) # Poner resultado
mov %dl, 13(%ebx)
pop %... # Restaurar registros
pop %...
ret
|
El principal inconveniente de esta técnica es que necesita tener estas zonas de memoria previamente definidas. Además, en el caso de invocación anidada de subrutinas, se necesitan múltiples espacios de parámetros y resultados pues mientras la ejecución de una subrutina no termina, éstos siguen teniendo validez.
El incluir esta definición junto con el código de una subrutina parecería una solución idónea, pues al escribir sus instrucciones se sabe el número y tamaño de parámetros y resultados. Pero existen subrutinas denominadas “recursivas” que se caracterizan por contener una invocación a ellas mismas con un conjunto de parámetros diferente.
La conclusión es que se precisan tantas zonas para almacenar parámetros y devolver resultados como invocaciones pendientes de terminar en cada momento de la ejecución. Pero este requisito de vigencia es idéntico al que tiene la dirección de retorno de una subrutina. Es más, la dirección de retorno se puede considerar un valor más que el programa llamador pasa al llamado para que éste lo utilice. En esta observación se basa la siguiente técnica de paso de parámetros.
El paso de parámetros a través de la pila tiene múltiples ventajas. En primer lugar, tanto parámetros como resultados se pueden considerar resultados temporales que tienen validez en un período muy concreto de la ejecución de un programa por lo que la pila favorece su manipulación. Además, dada una secuencia de llamadas a subrutinas, el orden de creación y destrucción de estos parámetros es el inverso tal y como permiten las instrucciones de gestión de la pila.
En general, para una subrutina que recibe n parámetro y devuelve m
resultados el programa llamador reserva espacio en la cima de la pila
para almacenar estos datos justo antes de ejecutar la instrucción
CALL y lo elimina justo a continuación.
Pero en la subrutina es necesario un mecanismo eficiente para acceder
a la zona de parámetros y resultados. Al estar ubicada en la pila lo
más intuitivo es utilizar el registro %esp que apunta a
la cima y el modo de direccionamiento base + desplazamiento mediante
la utilización de los desplazamientos pertinentes. Pero el
inconveniente de este método es que la cima de la pila puede fluctuar
a lo largo de la ejecución de la subrutina y por tanto los
desplazamientos a utilizar varían.
Para que el acceso a los parámetros no dependa de la posición de la
cima de la pila y se realice con desplazamientos constantes a lo
largo de la ejecución de la subrutina, las
primeras instrucciones almacenan una copia del
puntero de pila en otro registro (generalmente %ebp) y
al fijar su valor, los accesos a la zona de parámetros y resultados
se realizan con desplazamientos constantes. Pero para preservar el
valor de los registros, antes de crear este duplicado es preciso
guardar en la pila una copia de este registro. El ejemplo 8.7 muestra las instrucciones necesarias
para el caso de una subrutina que precisa tres parámetros de tamaño
32 bits y devuelve un resultado de 8 bits.
Ejemplo 8.7. Paso de parámetros a través de la pila
| Programa llamador | Programa llamado |
|---|---|
sub $4, %esp
push v3
push v2
push v1
call subrutina
add $12, %esp
pop resultado
|
subrutina:
push %ebp # Guardar registro %ebp
mov %esp, %ebp # Apuntar a punto fijo en pila
push %... # Salvar registros utilizados
push %...
mov 8(%ebp), ... # Acceso a los parámetros
mov 12(%ebp), ...
mov 16(%ebp), ...
... # Realizar cálculos
mov ..., 20(%ebx) # Poner resultado
pop %... # Restaurar registros
pop %...
mov %ebp, %esp # Restaurar %esp y %ebp
pop %ebp
ret
|
La primera instrucción del programa llamador modifica el puntero de
la pila para reservar espacio donde almacenar el resultado. Al ser
una posición de memoria sobre la que se escribirá el resultado no es
preciso escribir ningún valor inicial, de ahí que no se utilice la
instrucción push.
A continuación se depositan en la pila los valores de los parámetros. El orden en que se almacenan debe ser conocido por el programa llamador y el llamado. Tras la ejecución de la subrutina se eliminan de la pila los parámetros, que al desempeñar ningún papel, basta con corregir el valor de la cima dejando la pila preparada para obtener el valor del resultado.
Por su parte, el programa llamado guarda la copia del registro
%ebp para justo a continuación copiar el valor de
%esp y por tanto fija su valor a la cima de la pila. A
partir de este instante, cualquier dato que se ponga en la pila no
afecta el valor de %ebp y el desplazamiento para acceder
a los parámetros es respectivamente de 8, 12 y 16 pues en la posición
debajo de la cima se encuentra la dirección de retorno. Para
depositar el resultado se utiliza el desplazamiento 20. Tras terminar
el cálculo del resultado se procede a deshacer la estructura de datos
creada en la pila en orden inverso. Primero se descargan de la pila
los registros salvados y a continuación se restaura el valor del
registro %ebp dejando en la cima la dirección de retorno
que necesita la instrucción ret.
A la porción de memoria en la pila que contiene el espacio para la
devolución de resultados, los parámetros, la dirección de retorno, la
copia de %ebp se le denomina el “bloque de
activación”. Al registro %ebp que ofrece un punto
fijo de referencia a los datos se le denomina el
“puntero” al bloque de activación.
Además de la capacidad de definir y ejecutar subrutinas, los
lenguajes de programación de alto nivel permiten la definición de
variables locales. El ámbito de validez se reduce al instante en que
se está ejecutando el código de la subrutina. De nuevo se precisa un
mecanismo que gestione de forma eficiente estas variables. El ejemplo 8.8 muestra la definición de un método en
Java en el que las variables i, str y
p son de ámbito local.
Ejemplo 8.8. Definición de variables locales a un método
int traducir(Representante r, int radix) {
int i; // Variables locales
String str;
Punto p;
i = 0;
str = new String(...);
punto = ...
...
return i;
}
El ámbito de estas variables no impide que el valor de alguna de ellas sea devuelto como resultado tal y como muestra el método del ejemplo. La última línea copia el valor de la variable local en el lugar en el que se devuelve el resultado, y por tanto está disponible para el programa llamador.
El ámbito de estas variables es idéntico al de los parámetros y al de la dirección de retorno, por lo que para almacenar estas variables se pueden utilizar cualquiera de las tres técnicas descritas anteriormente: en registros, en posiciones arbitrarias de memoria y en la pila.
El almacenamiento en la pila se hace en el bloque de activación justo
a continuación de haber establecido el registro %ebp
como puntero al bloque de activación. De esta forma, como el número
de variables locales es siempre el mismo, utilizando desplazamientos
con valores negativos y el registro base %ebp se accede
a ellas desde cualquier punto de la subrutina.
De las técnicas descritas para la invocación de subrutinas, la que crea el bloque de activación en la pila es la más utilizada por los lenguajes de alto nivel. En la tabla 8.1 se muestran los pasos a seguir por el programa llamador y el llamado para crear y destruir el bloque de activación.
Tabla 8.1. Pasos para la gestión del bloque de activación
| Programa llamador | Programa llamado |
|---|---|
|
|
Tras restaurar el valor de los registros utilizados por la subrutina, el
estado de la pila es tal que en la cima se encuentra el espacio para las
variables locales y a continuación la copia del valor anterior de
%ebp. Como el propio %ebp apunta a esa misma
posición, la forma más fácil de restaurar la cima de la pila al valor
correcto es asignándole a %esp el valor de
%ebp. De esta forma no es preciso tener en cuenta el tamaño
de la zona reservada para las variables locales. Esta técnica funciona
incluso en el caso de que una subrutina no tenga variables locales.
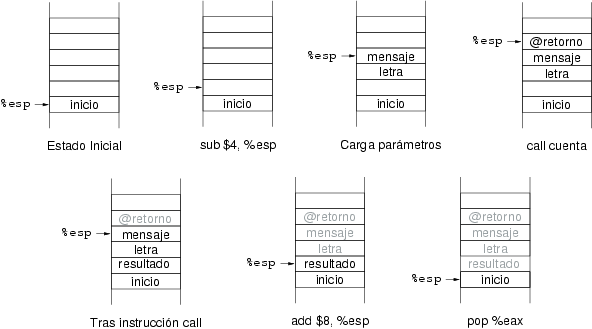
Considérese un programa que invoca a la subrutina cuenta que
dada la dirección de un string terminado en cero y un carácter, devuelve
el número de veces que el carácter aparece en el string como entero. La
pila que recibe la subrutina tiene, en orden creciente de desplazamiento
desde el puntero al bloque de activación, la dirección de retorno
(siempre está presente como primer valor), la dirección del string, el
carácter a comprobar como byte menos significativo del operando en la
pila y el espacio para el resultado. El fragmento de código para invocar
a esta subrutina se muestra en el ejemplo 8.9. Se asume que la letra a buscar está
almacenada en la etiqueta letra y el string en la etiqueta
mensaje.
Ejemplo 8.9. Invocación de la rutina cuenta
...
sub $4, %esp # Espacio para el resultado
push letra # Parámetros en el orden correcto
push mensaje
call cuenta # Invocación de la subrutina
add $8, %esp # Descarga del espacio para parámetros
pop %eax # Resultado en %eax
...
La instrucción push letra tiene por operando una etiqueta
que apunta a un dato de tamaño byte. Como los operandos de la pila son de
4 bytes, en ella se depositan la letra y los tres siguientes bytes. Esto
no tiene importancia porque la subrutina únicamente accede al byte de
menos peso tal y como se ha especificado en su definición. La figura 8.15 muestra la evolución de la pila desde el
punto de vista del programa llamador.
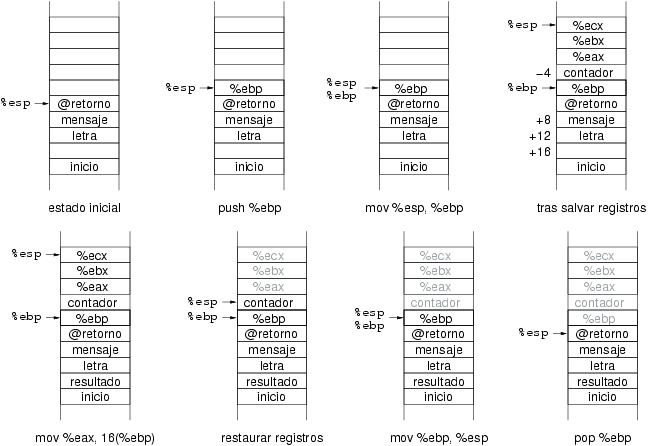
El código de la subrutina cuenta se muestra en el ejemplo 8.10.
Ejemplo 8.10. Código de la rutina cuenta
cuenta: push %ebp # Salvar %ebp
mov %esp, %ebp # Crear puntero a bloque de activación
sub $4, %esp # Espacio para variable local: contador
push %eax # Salvar registros utilizados
push %ebx
push %ecx
movl $0, -4(%ebp) # Contador = 0
mov 8(%ebp), %eax # Dirección base del string
mov 12(%ebp), %cl # Letra a comparar en %cl
mov $0, %ebx # Registro índice
bucle: cmpb $0, (%eax, %ebx) # Detectar final de string
je res
cmpb %cl, (%eax, %ebx) # Compara letra dada con letra en string
jne incr # Si iguales incrementar contador
incl -4(%ebp)
incr: inc %ebx # Incrementar registro índice
jmp bucle
res: mov -4(%ebp), %eax # Mover contador a resultado
mov %eax, 16(%ebp)
pop %ecx # Restaurar registros
pop %ebx
pop %eax
mov %ebp, %esp # Eliminar variables locales
pop %ebp # Restaurar %ebp
ret
La subrutina almacena el número de de veces que aparece la letra en el string dado como una variable local en la pila. Tras finalizar el bucle, su valor se transfiere al lugar en el que lo espera el programa llamador. La figura 8.16 muestra la evolución de la pila durante la ejecución de la subrutina.
Traducir el siguiente bucle en lenguaje de alto nivel a la porción de código equivalente en lenguaje ensamblador del Intel Pentium. Se asume que todas las variables son de tipo entero.
for (i = a + b; ((c + d) >= 10) && (i <= (d + e)); i = i + f - g - h ) {
g--;
f++;
a = b + 10;
}
Las variables han sido definidas de la siguiente forma:
a: .int 10 b: .int 20 c: .int 30 d: .int 40 e: .int 50 f: .int 60 g: .int 70 h: .int 80 i: .int 10
La solución puede utilizar cualquier modo de direccionamiento excepto el modo absoluto. Al tratarse de una porción de código aislada, no es preciso salvar ni restaurar el contenido de los registros. La solución debe ser lo más corta posible y utilizar el menor número de registros de propósito general.
La mayor parte de los lenguajes de alto nivel que ofrecen bucles de
tipo while también ofrecen otro bucle de
estructura similar denominado
do/while. La diferencia es que el bloque
comienza por la palabra clave do seguida de un bloque de
código entre llaves y termina con la palabra while seguida
de una condición booleana entre paréntesis.
El bloque de código se ejecuta al menos una vez y tras él se evalúa la
condición para determinar si se continúa iterando. Escribir la
estructura en codigo ensamblador resultante de traducir esta
construcción. Se puede asumir que el resultado de evaluar la condición
está almacenado en %eax.
Escribir las reglas para el paso de parámetros y devolución de resultado a través de la pila:
Por parte del programa que llama a la subrutina:
Por parte de la subrutina:
Un programador ha escrito la siguiente rutina:
rutina:
push %ebp
mov %esp, %ebp
add $13, 4(%ebp)
pop %ebp
ret
El programa principal que invoca a esta rutina contiene las siguientes instrucciones tal y como las muestra el compilador en su informe sobre el restulado del ensamblaje:
1 .data 2 0000 50726F67 msg: .asciz "Programa terminado.\n" 2 72616D61 2 20746572 2 6D696E61 2 646F2E0A 3 4 .text 5 .globl start 6 start: 7 0000 50 push %eax 8 0001 51 push %ecx 9 0002 52 push %edx 10 11 0003 E8FCFFFF call rutina # Llamada a rutina dada 11 FF 12 13 0008 68000000 push $msg 13 00 14 000d E8FCFFFF call printf 14 FF 15 0012 83C404 add $4, %esp 16 17 0015 5A pop %edx 18 0016 59 pop %ecx 19 0017 58 pop %eax 20 0018 C3 ret
Explicar detalladamente cuál es el resultado de la ejecución de este programa. ¿Ejecuta correctamente? ¿Qué escribe por pantalla? ¿Por qué?
El paso de resultados y devolución de resultados se puede hacer a través de registros, memoria o la pila, pero nada impide utilizar una técnica diferente para parámetros y resultados. Describir las reglas de creación del bloque de activación para los siguientes supuestos.
Parámetros en la pila y resultados a través de registros.
Parámetros en registro y resultados a través de la pila.
|
|
|
|
| Capítulo 7. Modos de Direccionamiento |  |
Apéndice A. Subconjunto de instrucciones del Intel Pentium |